ファクトはAIによる自動抽出です。誤りが含まれる可能性があります。正確な情報は原資料をご確認ください。
総務省
実績DX・デジタル
NICTが400億パラメータの大規模言語モデルを開発
400億
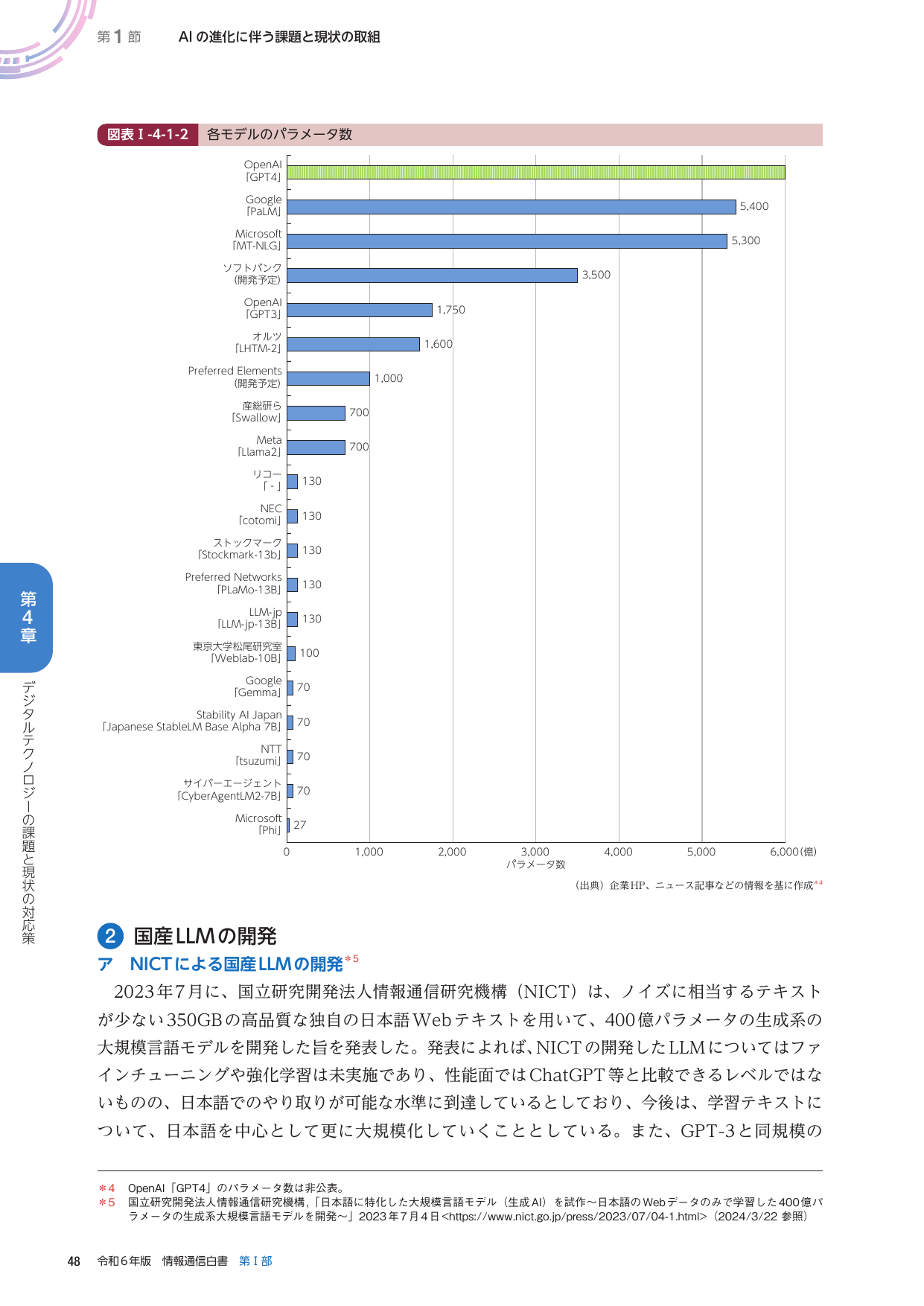
2023年7月に、国立研究開発法人情報通信研究機構(NICT)は、ノイズに相当するテキストが少ない350GBの高品質な独自の日本語Webテキストを用いて、400億パラメータの生成系の大規模言語モデルを開発した旨を発表した。
2023年2024年7月
2024/7月令和6年版 情報通信白書(全体版)
2023年7月に、国立研究開発法人情報通信研究機構(NICT)は、ノイズに相当するテキストが少ない350GBの高品質な独自の日本語Webテキストを用いて、400億パラメータの生成系の大規模言語モデルを開発した旨を発表した。
概要
NICTは2023年7月、高品質な日本語Webテキスト(350GB)を用いて400億パラメータの大規模言語モデルを開発したと発表した。
出典スライド
スライドテキスト
第1節 AIの進化に伴う課題と現状の取組 図表 I-4-1-2 各モデルのパラメータ数 第4章 デジタルテクノロジーの課題と現状の対応策 2 国産LLMの開発 ア NICTによる国産LLMの開発 2023年7月に、国立研究開発法人情報通信研究機構(NICT)は、ノイズに相当するテキスト が少ない350GBの高品質な独自の日本語Webテキストを用いて、400億パラメータの生成系の 大規模言語モデルを開発した旨を発表した。発表によれば、NICTの開発したLLMについてはファ インチューニングや強化学習は未実施であり、性能面ではChatGPT等と比較できるレベルではな いものの、日本語でのやり取りが可能な水準に到達しているとしており、今後は、学習テキストに ついて、日本語を中心として更に大規模化していくこととしている。また、GPT-3 と同規模の *4 OpenAI 「GPT4」のパラメータ数は非公表。 *5 国立研究開発法人情報通信研究機構、「日本語に特化した大規模言語モデル(生成AI)を試作~日本語のWebデータのみで学習した400億パ ラメータの生成系大規模言語モデルを開発~」2023年7月4日<https://www.nict.go.jp/press/2023/07/04-1.html> (2024/3/22 参照) 48 令和6年版 情報通信白書 第Ⅰ部 6,000(億) 5,000 4,000 3,000 2,000 1,000 0 パラメータ数 (億) (出典) 企業HP、ニュース記事などの情報を基に作成 *4 OpenAI [GPT4] Google [PaLM] Microsoft [MT-NLG] ソフトバンク (開発予定) OpenAI [GPT3] オルツ [LHTM-2] Preferred Elements (開発予定) 産総研ら [Swallow] Meta [Llama2] リコー 「-」 NEC [cotomi] ストックマーク [Stockmark-13b] Preferred Networks [PLaMo-13B] LLM-jp [LLM-JP-13B] 東京大学松尾研究所 [Weblab-10B] Google [Gemma] Stability AI Japan [Japanese StableLM Alpha 7B] NTT [tsuzumi] サイバーエージェント [CyberAgentM2-7B] Microsoft [Phi] 5,400 5,300 3,500 1,750 1,600 1,000 700 700 130 130 130 130 130 100 70 70 70 70 27